
新闻
新闻资讯
联系我们
联系人:陈先生
手机:13888889999
电话:020-88888888
邮箱:youweb@126.com
地址:广东省广州市番禺经济开发区
公司新闻
在神经网络中weight decay起到的做用是什么?momentum呢?normalization呢?
同理,momentum呢?normalization呢?
一、weight decay(权值衰减)的使用既不是为了提高你所说的收敛精确度也不是为了提高收敛速度,其最终目的是防止过拟合。在损失函数中,weight decay是放在正则项(regularization)前面的一个系数,正则项一般指示模型的复杂度,所以weight decay的作用是调节模型复杂度对损失函数的影响,若weight decay很大,则复杂的模型损失函数的值也就大。
二、momentum是梯度下降法中一种常用的加速技术。对于一般的SGD,其表达式为,
沿负梯度方向下降。而带momentum项的SGD则写生如下形式:
其中即momentum系数,通俗的理解上面式子就是,如果上一次的momentum(即
)与这一次的负梯度方向是相同的,那这次下降的幅度就会加大,所以这样做能够达到加速收敛的过程。
三、normalization。如果我没有理解错的话,题主的意思应该是batch normalization吧。batch normalization的是指在神经网络中激活函数的前面,将按照特征进行normalization,这样做的好处有三点:
1、提高梯度在网络中的流动。Normalization能够使特征全部缩放到[0,1],这样在反向传播时候的梯度都是在1左右,避免了梯度消失现象。
2、提升学习速率。归一化后的数据能够快速的达到收敛。
3、减少模型训练对初始化的依赖。
单说momentum,我觉得上面几位的说法(momentum可以克服local minima和critical point)值得商榷。
最简单的梯度下降法是
.
对于ill-conditioned问题,梯度下降法中每次迭代的方向都很接近于Hessian矩阵最小特征向量的垂直方向,对目标函数的改进很小。为此加入一个历史信息项
这里的就称为动量项,作用是通过历史搜索方向的积累,消除相继搜索方向中相反的方向,而一致的方向则相互累加。
对动量项的分析,有两个方面。
第一,动量项是共轭梯度法的近似 Steepest descent with momentum for quadratic functions is a version of the conjugate gradient method。共轭梯度法使用以前的搜索信息来修正当前的梯度方向,使得搜索方向之间相互共轭
,
其中 是共轭参数。共轭方向如下图,图片来自 Efficient BackProp, Efficient BackProp
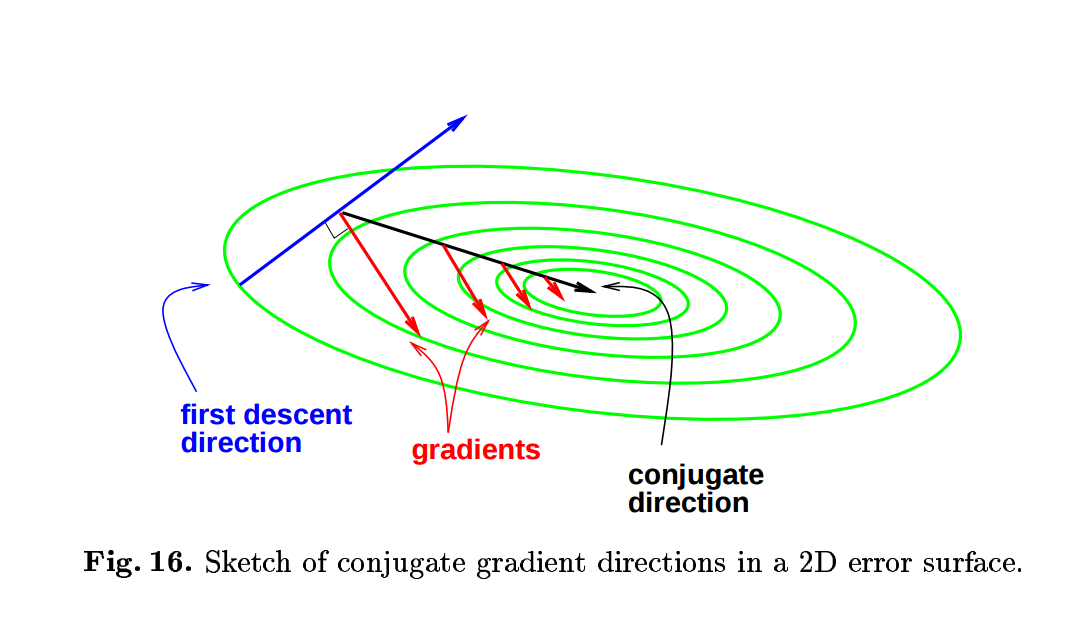
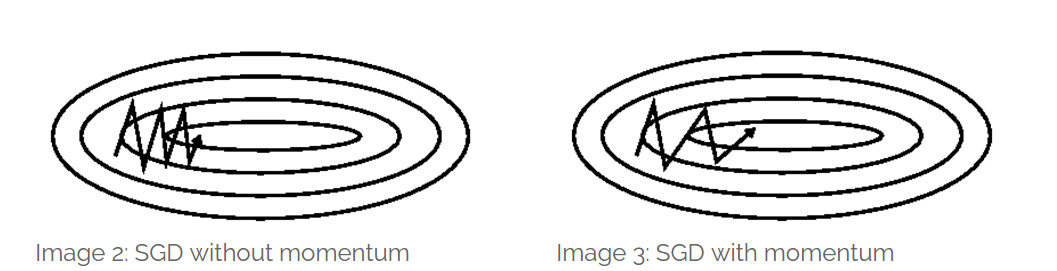
使用常数的值,这就是momentum方法。换句话说,momentum 实际是共轭梯度法的近似 。Momentum的作用也和共轭梯度法的作用相似,即通过使用历史搜索方法对当前梯度方向的修正来抵消在ill-conditioned 问题上的来回震荡。下图来自 An overview of gradient descent optimization algorithms
第二,使用动量项的优化方法是Newton方程/Hamilton 方程的离散化 On the momentum term in gradient descent learning algorithms。梯度下降法是梯度流
的离散化,即
.
而含有动量项的优化方法,相当于将方程
进行离散化。这是势能为保守力场中,质量为m的质点在摩擦系数为
的介质中的运动方程。对此方程的二阶近似分析指出,带有momentum的时候,可以使用更大的学习率
。
从这些分析出发,momentum主要是提高收敛速率的,并没有什么证据证明momentum对 local minima 比gradient descent 更加有效。Momentum term允许使用更大的学习率这一点对 critical point 可能有正面效果,不过具体的分析没有见到。在按点附近momentum的行为可见An overview of gradient descent optimization algorithms 最下面的动态图,其效果似乎值得怀疑。如果有人看到相关分析,请提醒我一下。
我的相关回答:
神经网络的训练可以采用二阶优化方法吗(如Newton, Quasi Newton)?
有哪些学术界都搞错了,忽然间有人发现问题所在的事情? - 知乎用户的回答 - 知乎
启发式优化算法中,如何使之避免陷入局部最优解? - 知乎用户的回答 - 知乎

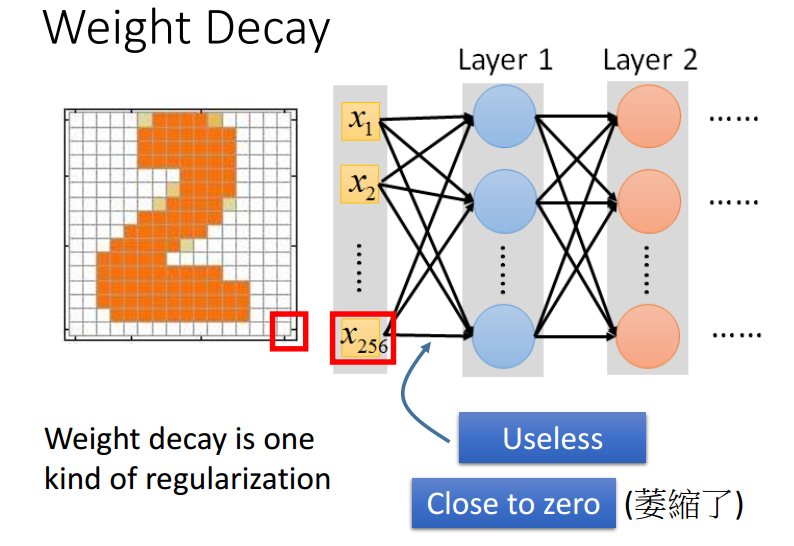

引用李宏毅的三张ppt
说说我对Weight Decay超参的理解。
在设置上,Weight Decay是一个L2 penalty,是对参数取值平方和的惩罚。
然而我们有大量的论文去考察参数的取值,发现
1. 不是高斯分布。
2. 取值可以量子化,即存在大量可压缩空间
3. 因为Relu, BN的存在使得其有界。
那么根据Loss function的设置求导之后,我们得到一个公式:
W( t+ 1)=W ( t ) ? lr ? delta(W)? lr ? wd ? W ( t )
也就是说,实际上我们可以把它化简为W(t)首先以(1- lr ? wd )的比例等比例收缩,然后再根据学习率、梯度方向进行一次调整。
这个一收缩不要紧,我们现在做CNN已经不用Sigmoid+AveragePooling了,我们用的是Relu+MaxPooling,也就是说这一收缩,可能有的干脆就从激发变成了不激发。可有可无的激发也就消失掉了,有点像DropOut,当然如果这个Neuron真有用也可以回头再靠梯度把它学成激发状态。所以说有了这个东西会规避过拟合。
现在很少有流行模型使用DropOut了吧?窃以为,道理就在这。
最后,假设W只能取0和1两个值,那么L1-Penalty和L2-Penalty其实是等价的。实际上的W取值,是处于我说的这种极端情况和高斯分布之间的,所以按找传统统计里L2-Penalty的思路去思考Weight Decay是不对的。现在CNN里面有很多paper在滥用高斯假设,慎读。
========================================
补记:我通过对浅层宽模型设置2-3倍默认的Weight Decay往往效果是最好的。太大了实际会严重干扰第一个Learning Rate阶段的精度。太小了(也就是很多论文的默认设置)会距离收敛最优情形有差距。CIFAR100 Top-1 84.36%是在Weight Decay=0.001上获得的。也就是说,在实践里我比其他人更喜欢加大Weight Decay。
Weight decay 就是在进行梯度下降时用一个 值(介于 0 到 1 之间)乘以当前计算中的每一个weight 。这么一来倒有几分 L2 regularization 的意思。
举个炒鸡简单的栗子。
f(a):=12n∑
其中,a 就是我们要优化的参数。
梯度下降走一波~~
其中,A= B=
m 表示迭代次数
经过好久好久好久的梯度下降,假设你的学习率取得合适哈, 收敛于
上市就等于
显然,解为 (假设 B 不等于 0 )
~~~~~~~~问题当然没有结束~~~~~~~~~~~
现在,如果在每次迭代时将 乘以一个乘子
,那么
的解就是
不妨令 =
(分子分母同除以
)
便是简单线性回归模型(无截距版。。)的最优解了。如此观之,它就是用来防止过拟合的。一般而言,Weight decay 体现了一种先验思想,它迫使网络的权重接近于0。网络越 sparse 泛化性能往往越好,同时权重过大通常是一个问题。
但是一般来说 Weight decay 的影响不大,其它的正则化技术 Dropout 和 BN 一般都比它强。。。
至于 momentum, 就是在梯度下降公式上乘一个接近 1 的数(0.999)~,以便跳过局部最优点。
normalization 就是一楼大佬的啦~
新闻资讯
-
2024-07-01 13:15:42
重磅利好!甘肃住房公积金贷款提取政策优化
-
2024-07-01 13:15:21
2022年食品行业抖音直播新玩法解读
-
2024-07-01 13:15:07
微信SEO,搜一搜,公众号排名优化策略详解
-
2024-07-01 13:14:28
The Functional Positioning and Optimization of Streets in th
-
2024-07-01 13:14:11
茶馆_1
-
2024-07-01 13:14:04
事业单位房产集中管理实践与探索

 QQ客服
QQ客服 

