
新闻
新闻资讯
联系我们
联系人:陈先生
手机:13888889999
电话:020-88888888
邮箱:youweb@126.com
地址:广东省广州市番禺经济开发区
公司新闻
MMDetection 系列之高级指南(自定义运行设置之优化器、其他设置、学习率、工作流、有用的和自定义钩子)
Hook programming是一种在程序的一个或多个位置设置挂载点的编程模式。当程序运行到某个挂载点时,会自动调用在运行时注册到该挂载点的所有方法。钩子编程可以增加程序的灵活性和扩展性,因为用户可以将自定义方法注册到要调用的挂载点,而无需修改程序中的代码。
MMEngine 将许多实用程序封装为内置挂钩。这些钩子分为两类,即默认钩子和自定义钩子。前者是指默认注册到Runner的,后者是指用户按需注册的。
每个钩子都有相应的优先级。在每个挂载点,优先级较高的钩子会先被Runner. 当共享相同的优先级时,钩子按照它们的注册顺序被调用。优先级列表如下。
HIGHEST (0)
VERY_HIGH (10)
HIGH (30)
ABOVE_NORMAL (40)
NORMAL (50)
BELOW_NORMAL (60)
LOW (70)
VERY_LOW (90)
LOWEST (100)
1、 default hooks(默认hooks)
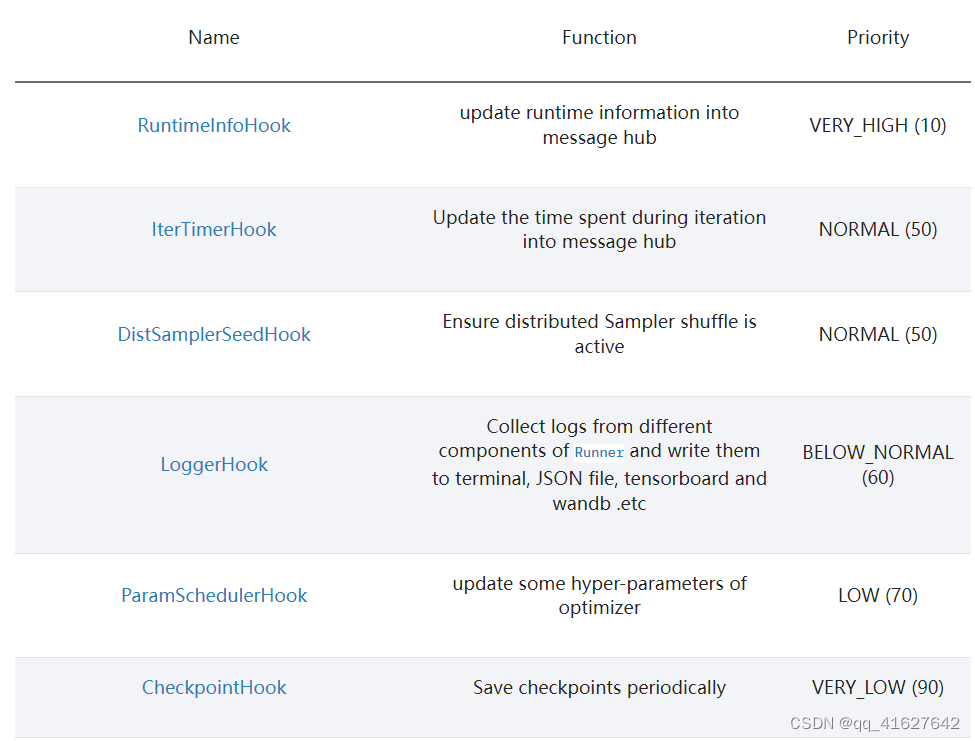
2、 custom hooks(自定义hooks)
 注意:不建议修改default hooks的优先级,因为较低优先级的钩子可能依赖于较高优先级的钩子。例如,CheckpointHook需要具有比 ParamSchedulerHook 更低的优先级,以便保存的优化器状态正确。此外,自定义挂钩的优先级默认为NORMAL (50)
注意:不建议修改default hooks的优先级,因为较低优先级的钩子可能依赖于较高优先级的钩子。例如,CheckpointHook需要具有比 ParamSchedulerHook 更低的优先级,以便保存的优化器状态正确。此外,自定义挂钩的优先级默认为NORMAL (50)
两种类型的 hooks 在 Runner 中的设置不同,default hooks的配置传递给default_hooks parameter of the Runner ,custom_hooks的配置传递给参数custom_hooks,如下。
3、Hook介绍
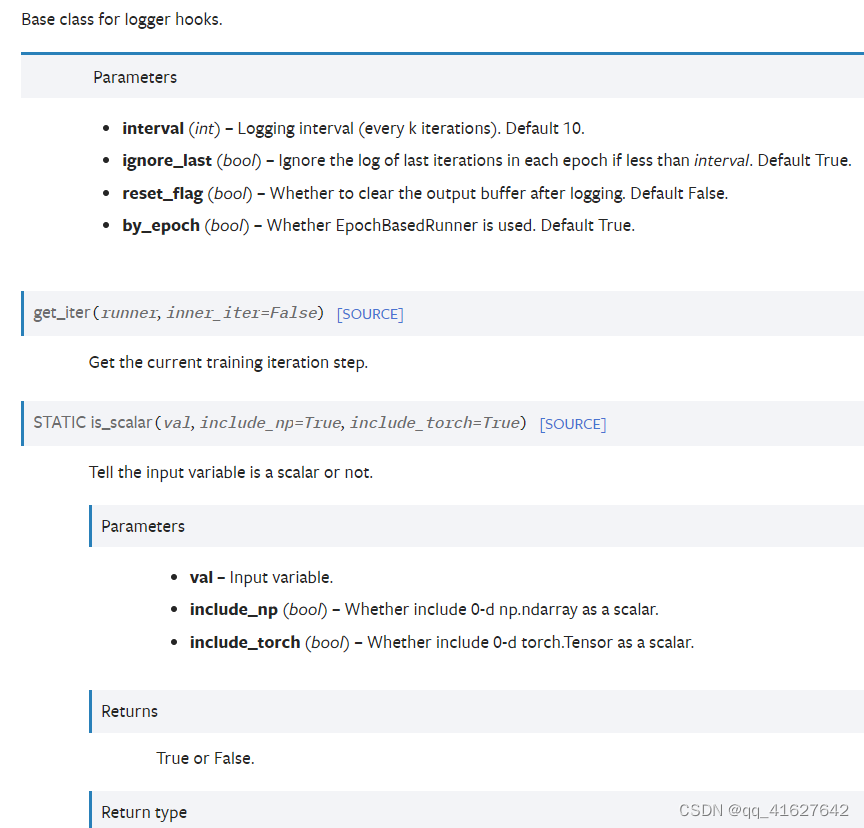
1、 LoggerHook
LoggerHook从Runner不同组件收集日志并将其写入终端、JSON文件、tensorboard和wandb等。
如果我们想每20次迭代输出(或保存)日志,我们可以设置参数interval并配置如下。
如果您对 MMEngine 如何管理日志记录感兴趣,可以参考日志记录。
2、 CheckpointHook
CheckpointHook以给定的时间间隔保存检查点。在分布式训练的情况下,只有主进程才会保存检查点。其主要特点CheckpointHook如下。
更多功能请阅读CheckpointHook API文档。
下面分别对上述六大特点进行介绍。
(1)按时间间隔保存检查点,支持按epoch或迭代保存
interval (int) – The saving period. If by_epoch=True, interval indicates epochs, otherwise it indicates iterations. Defaults to -1, which means “never”.
假设我们总共训练了 20 个 epoch,并且想要每 5 个 epoch 保存一次检查点,下面的配置将帮助我们实现这个要求。
(2)保存最近的检查点
如果只想保留一定数量的检查点,可以设置该max_keep_ckpts参数。当保存的检查点数量超过max_keep_ckpts 时,之前的检查点将被删除。
上面的配置显示,如果总共训练 20 个 epoch,则模型将在 epoch 5、10、15 和 20 保存,但检查点将在 epoch 15 时删除,在 epoch 20 时检查点将被epoch_5.pth删除epoch_10.pth,这样只有epoch_15.pth和epoch_20.pth会被保存。
(3)保存最佳检查点
save_best (str, List[str], optional) – If a metric is specified, it would measure the best checkpoint during evaluation. If a list of metrics is passed, it would measure a group of best checkpoints corresponding to the passed metrics. The information about best checkpoint(s) would be saved in runner.message_hub to keep best score value and best checkpoint path, which will be also loaded when resuming checkpoint. Options are the evaluation metrics on the test dataset. e.g., bbox_mAP, segm_mAP for bbox detection and instance segmentation. AR@100 for proposal recall. If save_best is auto, the first key of the returned OrderedDict result will be used. Defaults to None
如果想保存验证集的最佳检查点用于训练过程,可以设置该save_best参数。如果设置为’auto’,则根据验证集的第一个评估指标(评估器返回的评估指标是有序字典)判断当前检查点是最佳的。
也可以直接指定save_best 的值作为评估指标,例如在分类任务中,可以指定save_best=‘top-1’,则当前检查点将根据最佳’top-1’ 的值判断为best。
除了该save_best参数之外,与保存最佳检查点相关的其他参数还有rule、greater_keys和less_keys,用于暗示值越大越好。例如,如果指定save_best=‘top-1’,则可以指定rule='greater’表示值越大,检查点越好。
(4**)指定检查点保存路径**
默认情况下保存检查点work_dir,但可以通过设置更改路径out_dir。
(5)设置发布检查点
如果您想在训练后自动生成可发布的检查点(删除不必要的键,例如优化器状态),您可以设置参数published_keys来选择保留哪些信息。注意:您需要相应地设置save_best或save_last参数,以便生成可释放的检查点。设置save_best将生成最优检查点的可释放权重,设置save_last将生成可释放的最终检查点。这两个参数也可以同时设置。
(6)控制检查点保存开始的纪元数或迭代数
如果要设置epoch或迭代的数量来控制保存权重的开始,可以设置该save_begin参数,默认为0,表示从训练开始就保存检查点。例如,如果您总共训练了 10 个 epoch,并且save_begin设置为 5,则将保存 epoch 5、6、7、8、9 和 10 的检查点。如果interval=2,则仅保存 epoch 5、7 和 9 的检查点。
3、ParamSchedulerHook
ParamSchedulerHook会迭代 Runner 的所有优化器参数调度器,并调用它们的step方法按顺序更新优化器参数。有关参数调度程序的更多详细信息,请参阅参数调度程序。
ParamSchedulerHook默认注册到Runner上,没有可配置的参数,所以不需要配置。
4、 IterTimerHook
IterTimerHook用于记录加载数据并迭代一次所花费的时间。
IterTimerHook默认注册到Runner上,没有可配置的参数,所以不需要配置。
5、DistSamplerSeedHook
DistSamplerSeedHook在分布式训练时调用Sampler的step方法来保证shuffle操作生效。
DistSamplerSeedHook默认注册到Runner上,没有可配置的参数,所以不需要配置。
6、 RuntimeInfoHook
RuntimeInfoHook 会将当前运行时信息(例如epoch、iter、max_epochs、max_iters、lr、metrics等)更新到Runner中不同挂载点的消息中心,以便其他无法访问Runner的模块可以获得这些信息。
RuntimeInfoHook默认注册到Runner上,没有可配置的参数,所以不需要配置。
7、 EMAHook
EMAHook在对模型训练时进行指数移动平均运算,目的是提高模型的鲁棒性。请注意,指数移动平均生成的模型仅用于验证和测试,不影响训练。
EMAHook默认使用ExponentialMovingAverage,可选值为StochasticWeightAverage和MomentumAnnealingEMA。通过设置ema_type可以使用其他平均策略。
更多用法请参见EMAHook API 参考。
8、EmptyCacheHook
EmptyCacheHook调用torch.cuda.empty_cache()释放所有未占用的缓存 GPU 内存。释放内存的时间可以通过设置before_epoch、after_iter、 和after_epoch 等,分别表示每个 epoch 开始之前、每次迭代之后和每个 epoch 之后。
9、 SyncBuffersHook
SyncBuffersHook在分布式训练期间在每个时期结束时同步模型的缓冲区,例如running_mean和BN层的running_var缓冲区。
SyncBuffersHook synchronizes the buffer of the model at the end of each epoch during distributed training, e.g. running_mean and running_var of the BN layer.
10、 DetVisualizationHook
DetVisualizationHook用DetLocalVisualizer可视化预测结果,DetLocalVisualizer当前支持不同的后端,例如TensorboardVisBackend和WandbVisBackend(有关更多详细信息,请参阅文档字符串vis_backend)。用户可以添加多个后端来进行可视化,如下所示。
1、Implement a new hook(2.3.0)
在某些情况下,用户可能需要实现一个新的钩子。MMDetection从2.3.0版本开始支持在training(#3395)中定制钩子。因此,用户可以直接在mmdet或基于mmdet的代码库中实现钩子,并且只需要在培训中修改配置即可使用钩子。在v2.3.0之前,用户需要在培训开始之前修改代码来注册钩子。这里我们给出一个在mmdet中创建一个新钩子并在培训中使用它的例子。
v3:如果 MMEngine 提供的内置钩子不能满足您的需求,我们鼓励您通过简单地继承钩子基类并重写相应的挂载点方法来自定义自己的钩子。例如,如果您想在训练期间检查损失值是否有效(即不是无限),您可以简单地重写after_train_iter以下方法。检查将在每次训练迭代后执行。
根据钩子的功能,用户需要在before_run, after_run, before_train, after_train , before_train_epoch, after_train_epoch, before_train_iter, and after_train_iter中指定钩子在训练的每个阶段将执行的操作。还有更多可以插入钩子的点,请参阅基本钩子类以获取更多详细信息。

2. Register the new hook(注册新钩子)
然后我们需要导入MyHook。假设文件在mmdet/core/utils/my_hook.py中,有两种方法:
Modify mmdet/core/utils/init.py to import it.
The newly defined module should be imported in mmdet/core/utils/init.py so that the registry will find the new module and add it:
Use custom_imports in the config to manually import it

V3: 我们只需将钩子配置传递给Runner custom_hooks的参数,它将在 Runner 初始化时注册钩子
然后在迭代后检查损失值。
注意,自定义钩子的优先级是默认的,如果你想改变钩子的优先级,那么你可以在config中设置priority键。NORMAL (50)
您还可以在定义类时设置优先级。
3. Modify the config(修改配置文件)
你也可以设置钩子的优先级,将键的优先级设置为“NORMAL”或“HIGHEST”,如下所示
By default the hook’s priority is set as NORMAL during registration.
3、 在MMCV中使用hook
如果该hook已经在MMCV中实现,你可以直接修改配置来使用该hook,如下所示
修改默认运行时hook
Example: NumClassCheckHook
我们实现了一个名为NumClassCheckHook的自定义hook来检查head中的num_classes是否与dataset中的CLASSSES长度匹配。
We set it in default_runtime.py.
4、Modify default runtime hooks(修改默认的运行时钩子)
在这些hook中,只有logger hook 具有VERY_LOw优先级,其他hook的优先级为NORMAL。上述教程已经介绍了如何修改optimizer_config、momentum_config和lr_config。在这里,我们揭示了如何使用log_config、checkpoint_config和evaluate来做什么。
1、 Checkpoint config
MMCV运行器将使用checkpoint_config来初始化CheckpointHook.CheckpointHook
用户可以将max_keep_ckpts设置为只保存少量的检查点,或者通过save_optimizer来决定是否存储优化器的状态字典。
CheckpointHook
注意:
在v1.3.16之前,out_dir参数表示检查点存储的路径。但是,从v1.3.16开始,out_dir表示根目录,保存检查点的最终路径是out_dir和runner.work_dir的最后一级目录的连接。假设out_dir的值为“/path/of/A”,runner的值为。work dir为“/path/of/B”,则最终路径为“/path/of/A/B”。
2、 Log config
log_config封装了多个日志记录器钩子,并允许设置间隔。现在MMCV支持WandbLoggerHook, MlflowLoggerHook和TensorboardLoggerHook。详细用法可以在文档中找到LoggerHook。
LoggerHook
3、 Evaluation config
评估的配置将用于初始化EvalHook。除键间隔外,其他参数(如metric)将被传递给数据集.evaluate ()
我们已经支持使用所有由PyTorch实现的优化器,唯一的修改就是更改配置文件的优化器字段。例如,如果您想要使用ADAM(注意性能可能会下降很多),修改可以如下所示。
要修改模型的学习率,用户只需修改optimizer配置中的1r即可。用户可以直接在PyTorch的API文档添加链接描述后面设置参数。
1、Define a new optimizer(定义一个新的优化器)
一个定制的优化器可以定义如下。假设您想添加一个名为MyOptimizer的优化器,它有参数a、b和c。您需要创建一个名为mmdet/core/optimizer的新目录。然后在文件中实现新的优化器,例如在mmdet/core/optimizer/my_optimizer.py中:
2. 将优化器添加到注册表
要找到上面定义的模块,首先应该将该模块导入主命名空间。实现这一目标有两种选择。
修改mmdet/core/optimizer/init.py来导入它。新定义的模块应该导入到mmdet/core/optimizer/init.py中,这样注册表就会找到新模块并添加它:
Use custom_imports in the config to manually import it (使用配置中的custom_imports手动导入它)
The module mmdet.core.optimizer.my_optimizer will be imported at the beginning of the program and the class MyOptimizer is then automatically registered. Note that only the package containing the class MyOptimizer should be imported. mmdet.core.optimizer.my_optimizer.MyOptimizer cannot be imported directly.
实际上,用户可以使用这种导入方法使用完全不同的文件目录结构,只要模块根可以位于PYTHONPATH。
3.在配置文件中指定优化器
然后你可以在配置文件的优化器字段中使用MyOptimizer。在配置文件中,优化器由字段优化器定义,如下所示:
To use your own optimizer, the field can be changed to
2、Customize optimizer constructor (定制优化器的构造函数)
一些模型可能有一些参数特定的设置来优化,例如BatchNorm层的权重衰减。用户可以通过定制优化器构造函数来实现这些细粒度的参数调整。
这里实现了默认的优化器构造函数default_constructor.py ,它也可以作为新的优化器构造函数的模板。

1、案例分析(Layer_decay_optimizer_constructor.py)

1、构造builder.py优化器函数
2、构造Layer_decay_optimizer_constructor.py优化器函数
3、将构造函数导入__init__.py
4、在配置文件中的使用
##3、Additional settings
1、 使用梯度剪辑来稳定训练:有些模型需要梯度剪辑来剪辑梯度来稳定训练过程。
如果您的配置继承了已经设置了optimizer_config的基本配置,您可能需要_delete_=True来覆盖不必要的设置。有关更多细节,请参阅配置文档。
2、 使用动量计划来加速模型收敛:
我们支持动量调度,根据学习速率修改模型的动量,使模型更快地收敛。动量调度器通常与LR调度器一起使用,例如,在三维检测中使用以下配置来加速收敛。更多细节,请参考CyclicLrUpdater和CyclicMomentumUpdater的实现。
默认情况下,我们使用1xschedule的步进学习速率,这在MMCV中调用了StepLRHook。我们支持许多其他的学习速率计划,如余弦退火和Poly计划。下面是一些例子
Poly schedule:
ConsineAnnealing schedule:
工作流是指定运行顺序和时间的(阶段,时间)列表。默认情况下,它被设置为
这意味着要进行1个阶段的训练。有时,用户可能想要检查验证集中模型的一些指标(例如损失、准确性)。在这种情况下,我们可以将工作流设置为
因此,1个训练阶段和1个验证阶段将反复运行。
1、The parameters of model will not be updated during val epoch.
2、配置中的关键字total_epoch只控制培训epoch的数量,不会影响验证工作流。
3.工作流[(‘train’, 1), (‘val’, 1)]和[(‘train’, 1)]不会改变EvalHook的行为,因为EvalHook是由after_train_epoch调用的,并且验证工作流只影响通过after_val_epoch调用的钩子。因此,[(‘train’, 1), (‘val’, 1)]和[((‘train’, 1)]之间的唯一区别是,跑步者将在每个训练周期后计算验证集上的损失。
新闻资讯
-
2024-07-01 13:15:42
重磅利好!甘肃住房公积金贷款提取政策优化
-
2024-07-01 13:15:21
2022年食品行业抖音直播新玩法解读
-
2024-07-01 13:15:07
微信SEO,搜一搜,公众号排名优化策略详解
-
2024-07-01 13:14:28
The Functional Positioning and Optimization of Streets in th
-
2024-07-01 13:14:11
茶馆_1
-
2024-07-01 13:14:04
事业单位房产集中管理实践与探索

 QQ客服
QQ客服 

